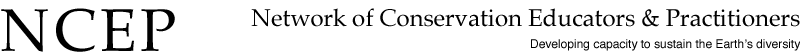


The field of Hydrology is primarily concerned with how water falls from the atmosphere, moves across the Earth and returns to the atmosphere. Biological processes of animals and plants have evolved over millions of years to adapt to, and depend on, when the right amount of water is available. Since all life on Earth depends on the existence of water, where water exists and when it exists are two of the most critical factors in determining if life can exist at any given location. Hydrologists seek to understand how water is provided by the atmosphere, where and how it moves across the surface of the earth, and attempt to predict when and how much will be available in the future.
In this unit we will discuss:
The water cycle is something most people learn about early in school, but it is also something so complex that people spend their careers trying to understand the details of how it works. We know that water is the most abundant liquid on the Earth, and it can present itself in many different forms or phases, including a solid, a liquid, or a vaporized gas. From basic chemistry, we know that it turns from a solid to a liquid at 0 degrees Celsius (32 degrees Fahrenheit) and it turns from a liquid to a gas at 100 degrees Celsius (212 degrees Fahrenheit). It has some very unique properties such as the fact that the solid form (ice) has a lighter density than its liquid form (water). Most substances get denser as they freeze. Imagine how different the polar ice caps would behave if ice sank to the bottom of the ocean!
We also know that the water cycle is a process that has been occurring for billions of years. Although water molecules can form and be destroyed, most water that we encounter has been transferred from one phase to another countless times throughout the history of the Earth. If we look at a snapshot of the Earth, water is distributed as follows:
As you can see, only 96.5% of the total amount of water is in the oceans, seas, and bays. Even more interesting is the amount of water that is in a liquid freshwater form (i.e. lakes and rivers) where it is available for terrestrial life to use (0.008%). If you consider how long water is stored in the polar regions and in glaciers (hundreds of years to hundreds of thousands of years), and in the saline oceans (up to millions of years), or deep groundwater aquifers (tens of thousands of years), water passes through the Earth in a non-saline liquid phase through rivers, streams, and lakes for a very brief time (minutes to hundreds of years).
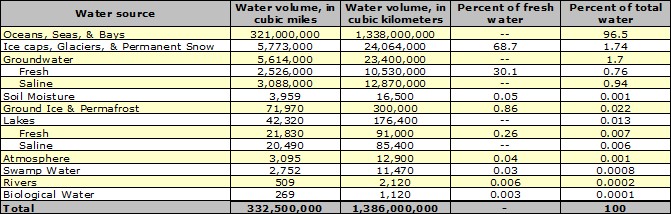
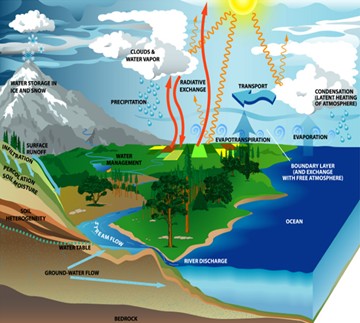
Starting with precipitation, water condenses from the water vapor in the sky in the form of rain, snow, or hail. The form of the precipitation that falls to the Earth is dependent on air temperature both in the clouds where the water condenses and on the air temperature of the Earth.
Water also re-enters the atmosphere from either its liquid phase or its solid phase. When air temperature raises and/or humidity in the air decreases, water evaporates directly from the ocean, soils, lakes, and rivers to the atmosphere. Similarly, when humidity decreases but air temperature remains below the freezing point, water from snow and ice can sublimate directly into the atmosphere.
The presence of vegetation greatly increases the rate of transfer of water from liquid phase to the gaseous vapor phase. Plants draw water from the soil moisture and transpire it to the atmosphere. The combined effect of evaporation and transpiration is often termed evapotranspiration. Depending on the type of vegetation, forested hillside can transpire much more water than bare hillsides. However vegetation also allows water to percolate deeper into the soil and provides shade that slows the rate of direct evaporation. In contrast, bare hillsides might not be able to absorb much moisture during rain events due to a “crusted” surface layer and may not stay moist for more than a few months during a rainy season due to a lack of shade. Therefore the net effect of vegetation is often storing water in bio-mass and releasing it to the atmosphere year-round. In addition, the moisture transpired from a forest increases the relative humidity of the atmosphere above it and therefore increases the potential for precipitation events. This is why deforested surfaces often take much longer to regrow than one would expect just based on the growth rate of the vegetation.
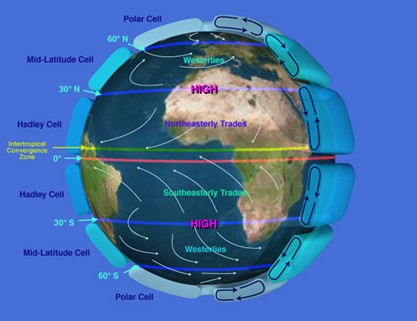
The motion of the Earth causes water vapor to migrate from one part of the atmosphere to the next on air currents. Depending on your location on the Earth and the particular season, the predominant winds in the atmosphere may be coming from one particular direction. One common explanation for why winds tend to be from one direction is the concept of “atmospheric cells.” This theory identifies a semi-closed cell termed a “Hadley cell” of moist air that tends to rise near the equator causing a zone of low pressure, moves towards the poles when it reaches approximately 14 kilometers, and descends around 30 degrees latitude as cooler dry air, causing a band of high pressure. Similarly a “Polar cell” is formed by warm air around 60 degrees latitude, causing a band of low pressure that raises up into the atmosphere and moves towards the poles where it descends as cold dry air. Between these two cells is another cell, the “Ferrel cell,” that is generally caused by the existence of the first two. With winds moving to zones of low pressure (near the equator, around 60 degrees north and south) from zones of high pressure (around 30 degrees north and south and at the poles), and coupling these cycles with the rotation of the Earth, a global circulation pattern can be estimated.
As moist air passes over a land mass, the air is forced upwards higher into the atmosphere. Since the air temperature decreases by an average of 6.49 degrees Celsius per 1000 meters (3.56 degrees Farenheit per 1000 ft), the cooler air is less able to hold water and reaches a point where 100% relative humidity is achieved. This results in heavier precipitation rates on windward sides of mountain ranges and drier conditions on leeward sided of mountain ranges. This effect is often referred to as a rain shadow.

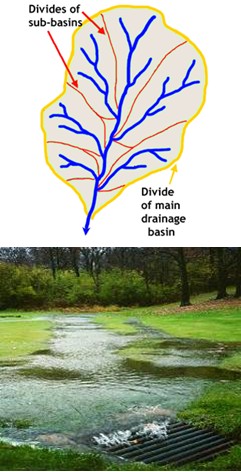
We all know that when precipitation falls from the sky in the form of either rain or snow, that precipitation may do many things. First, if water falls in the form of a light rain, much of that water may infiltrate into the soil. If this is true, much of the water might be evapotranspired and very little of it might be available for streamflow. On the other hand, if the rainfall becomes heavy, the soil may first start to absorb water, but once it becomes saturated, any additional water that falls might begin to run across the surface. This is called infiltration excess overland flow. The ability of the Earth to absorb rainfall is highly dependent on the type of soil. For example, a gravelly hillside might absorb water very fast while a field of fine soil particles (such as silt or clay) may not allow water to pass through very fast at all, thereby creating overland flow shortly after a rainstorm event begins. As water flows across the surface it tends to form small channels. When several small streams join together, we typically use the terms watershed or catchment to describe the physical surface area that contributes water to a particular point in a stream or small river. As more and more streams join together to form rivers, we often use the term basin to describe the contributing area. It is interesting to note that there are no strict differences between the definitions of a watershed, catchment, or basin. This is because there is a continuum of small to large areas that can contribute flows to river channels and you can see that a large basin is just made up of several smaller sub-basins, watersheds, or catchments.
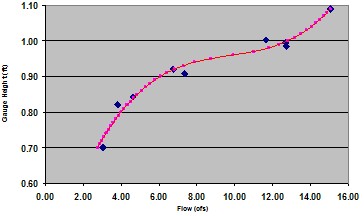
To really understand how much water flows across the Earth’s surface or out of one basin, we must measure it. At first this seems like an easy task, but it can be very difficult depending on the specific site conditions. To understand how much water is flowing through a channel at any given time, we have to establish a relationship between the depth of flow and the amount of flow. This way if we know how deep the water is, we know what the flow rate is through the channel. Since natural channels exist in all shapes and sizes we have to use one of two methods to understand this relationship: constrain the channel to a known geometry or develop a rating curve.
Hydraulic theories and laboratories are used to develop shapes that have unique depth-flow relationships that can be calculated mathematically. Flumes and weirs are structures that have these properties, so to make a natural channel into one where the flow can be easily measured, one of these structures can be built into the channel.

Flows in natural channels can be measured with the use of velocity meters throughout cross sections of the channel. By determining the flows at one particular point of time along with the depth of flow (also called stage), we know one point on a rating curve. By making many measurements at different flows and depths, we can compile this information to develop a rating curve for many natural channels.
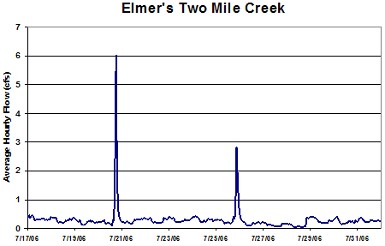
We can measure how much water passes through a stream or river channel to understand the rainfall-runoff relationship that is unique for that area. The pattern that water flows out of a watershed is often called the hydrograph. These are typically shown as a plot of time vs. flow. Look at the figures below. These are hydrographs for very different sized rivers. In the figure on the left you can see how two rainstorms created spikes in the hydrograph for Elmer’s Two Mile Creek. Now look at the figure on the right and see how this river is obviously much larger. In this hydrograph you can clearly see the seasonality of the flows.
We discussed the possibility that precipitation falls as snow during cold periods of the year and may accumulate over many months before the air temperature increases sufficiently that the snow begins to melt. This is particularly important in basins that have high altitudes or cold winters, such as much of the Colorado River Basin. We will discuss this particular phenomenon more next.
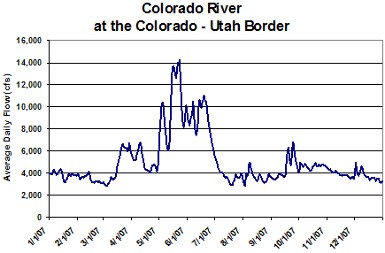
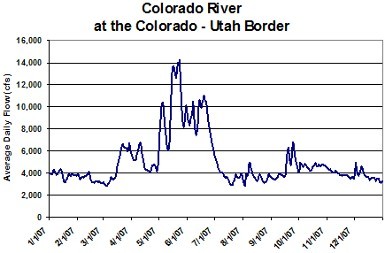
All of the concepts of the water cycle apply to the Colorado River Basin. The majority of the moisture that falls upon the Colorado River Basin originates from the Pacific Ocean and travels eastward through the atmosphere. Orographic lifting of the moist air mass results in precipitation on the western slope of the Rocky Mountains. The Colorado River Basin is often called a snowmelt dominated system because so much of the surface area is at high elevation where the air temperature is below the freezing point for many months of the year and precipitation falls as snow. This snow often persists in a deep snowpack until the spring when the temperature raises above the melting point and the snow begins to percolate into the groundwater or become surface runoff. Look at the Hydrograph below for the Colorado River and notice when the high season flows begin. This corresponds to when the snow begins to melt. It is also clear from the graph when the last of the snowpack is melted from the high mountains.
Lower elevations in the Colorado River Basin typically receive little precipitation and are considered deserts. However these are often the scenes of spectacular thunderstorms that provide substantial amounts of rainfall during short periods of time. Unfortunately for water planners, these occasional deluges are not frequent enough to be considered a reliable source of freshwater and therefore Lower Basin water users have become highly dependent on receiving water supplies from the Colorado River that originate high in the Rocky Mountains.
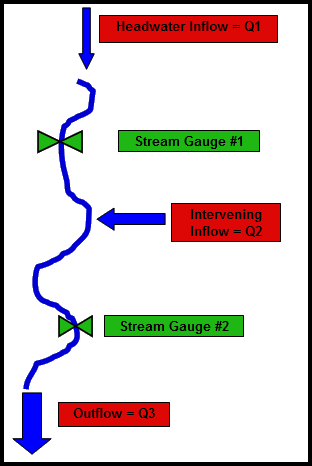
We develop models to allow us to estimate runoff from precipitation, but the direct knowledge of what flows have occurred in the past gives us the best information of what may happen in the future, therefore an important part of hydrology is being able to measure flows inside a river channel. People began to record flows in the Colorado River as early as 1898 and continue to do so today. Through a series of stream gauges along the River, we know how much water is passing by at each location at any given moment. Determining how much water enters (or leaves) a stream at any location is estimated by subtracting the flows measured between two nearby stream gauges.
Look at the simplified representation of a river in figure on the right. Imagine that we know how much water passes by the two stream gauges (in green) over one day and we want to determine the amount of water entering and leaving the river (in red) during that day. By looking at the figure we can see that:
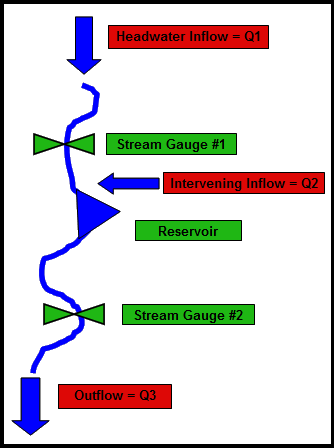
This is easy math, but now let’s make it a little more complicated. Now imagine that a reservoir is built between Stream Gauge #1 and Stream Gauge #2, like in the figure on the right. If we know how much water passes the gauges during the day, how much water is in the reservoir today [Storage (t)], and how much water was in the reservoir yesterday [Storage (t-1)], we want to again figure out how much water is entering and leaving the river between yesterday and today (Q1, Q2, Q3).
This is the process of using stream gauges to determine Naturalized Flows. This is important to us because if we want to estimate how much water will be available in the future, we need to understand how much water was naturally available in the past. In reality, this process gets much more complicated because there are many water users, losses to evaporation, and losses to groundwater that need to be considered.
The most basic method would be to take a sequence of flows that occurred in history and assume that they will reoccur in the future, in exactly the same magnitude and order as they did in the past.
So let’s say we have a 10-year record of flows from 1900 to 1909 and we want to use this to predict the future for the next 10 years (say from 2010 to 2019). We could assume that we could map the flow that occurred during historical years to the flows that will occur in future years as follows:
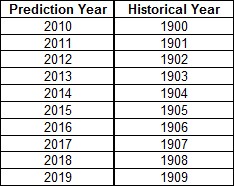
The inflows that occurred in these historical years can be put into our model for the prediction years and the model can be run from 2010 to 2019.
The one thing that we know about the future is that it will not exactly replicate the past. It often comes close, but it would be highly unlikely that 2010 will act exactly like 1900, 2011 will be exactly like 1901, etc. Fortunately with the power of models, we can run them many times under many different assumptions.
Another way of using historical flows to estimate future flows is to use probabilistic methods. By collecting all the historical total annual flow data, we can analyze it to see what the distribution of those data is. By categorizing the data into several bins, we can generate a histogram that roughly describes how the data is distributed. Several mathematical methods have been developed to describe the shape of various distributions with each one having a set of parameters that describe the shape (hence the name Parametric Methods). A simple example of a distribution function is called a Normal distribution, which is commonly referred to as a bell curve. The parameters for this typically are the mean (average), and the standard deviation. For the Colorado River, the data best fits to a distribution called a Contemporaneous Autoregressive Order 1 (CAR1).
Once a distribution function is determined then it is possible to create new hydrologic scenarios by sampling the distribution function many times. In other words, we can guess how much water might occur in any given year by choosing values in the range of possibilities with the likelihood of each value that could occur weighted by a probability of occurrence of that value. It is important to note that the low and high ends of the distribution functions typically extend beyond the flows we have historically measured.
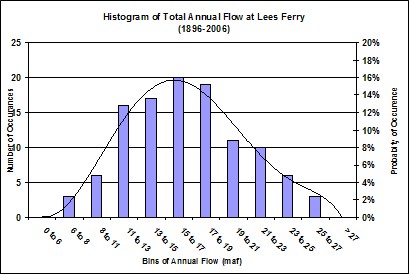
New methods are being developed to use the strengths of repeated history methods but also allow a certain degree of randomness. These methods typically use history as a general pattern but do not try to fit a mathematical distribution that requires estimating parameters, hence they are called Non-Parametric Methods. This technique conditionally re-samples historic data based on the state of the historic data. In other words, we try to use history as a guide, based on the general condition of each year (e.g. Very Dry, Dry, Normal, Wet, or Very Wet), but allow some degree of randomness to decide exactly how much water will be input into the model.
Let’s give an example. Imagine that we have a record of historical flows and we can categorize them based on 3 groups (dry, normal, and wet).
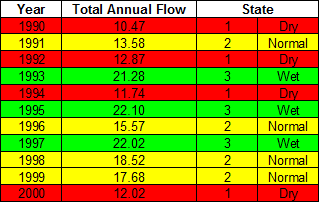
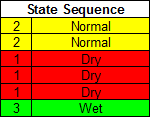
Now we want to develop several new scenarios that follow the same pattern as our state sequence that we are interested in. To develop a synthetic trace, at each time step we look at our historical list and pick years that fit the category that we want to simulate.
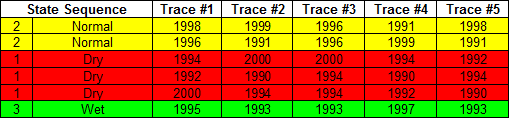
Here we have generated five synthetic (traces) that represent the pattern we are interested in by populating them with years that had historical flows that match the categories of the pattern. In other words, all the traces now have the Normal – Normal – Dry – Dry – Dry – Wet pattern. All we have to do now is to take the flows that occurred in those historical years and put them into our model.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}